REFRAG: Recursive Fragmentation for Efficient Retrieval-Augmented Decoding
Problem Statement
Retrieval-Augmented Generation (RAG) pipelines empower LLMs by pulling external knowledge into the context window. But a fundamental issue persists:
- Retrieved documents are long and redundant.
- Compressing them naïvely either loses crucial details or wastes context tokens.
- The challenge is preserving semantic fidelity under a strict token budget.
Mathematically: if each retrieved document is mapped into fragments and the LLM can only handle tokens, we want to minimize the information loss
where is the full set of fragment embeddings and is their compressed reconstruction, subject to .
This is essentially a low-rank approximation under a budget constraint.
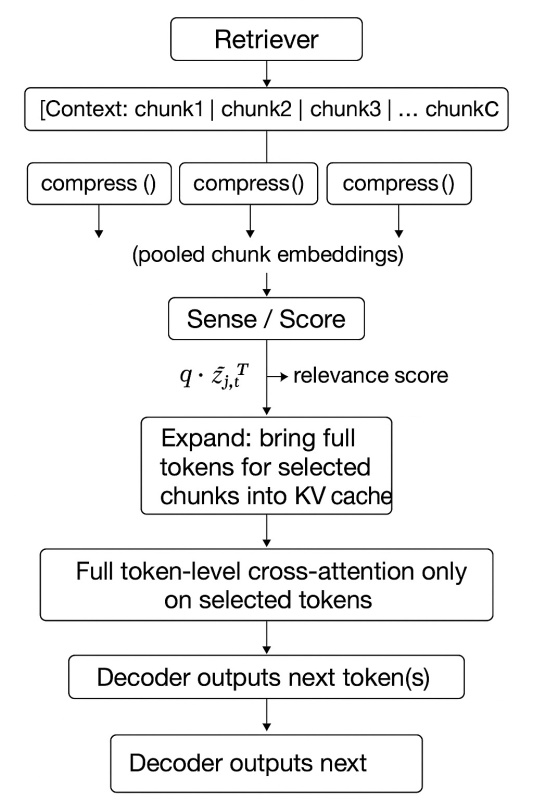
Big Idea: Fragment then Compress
Instead of compressing entire documents:
- Fragment each document into semantically coherent chunks.
- Compress each chunk into a small latent embedding.
- Score relevance between query and compressed chunks.
- Select & Expand the most promising ones back to full token detail.
This way, the model filters through compressed summaries but attends to full tokens only for the relevant few.
Mathematical Intuitions
1. Fragment Embeddings
Each fragment is encoded as
where is a pretrained encoder.
2. Compression Mapping
We compress via linear projection:
Interpretation: this reduces dimension but preserves dominant variance directions.
Error bound (from matrix approximation theory):
where are singular values of . So compression error is exactly the “energy” in discarded dimensions.
3. Diversity-Preserving Selection
Selecting top- fragments is not enough; we need coverage. Define objective:
- First term = relevance (dot product with query ).
- Second term = diversity via determinant (DPP-style).
- trades off relevance vs. coverage.
4. Cross-Attention Expansion
After selection, expand full tokens from chosen fragments and feed to LLM with cross-attention:
This focuses LLM compute on the most relevant token spans.
The ReFrag Pipeline
Complexity Analysis
Standard Full Attention
- Cost: for tokens.
- Memory: .
ReFrag Attention
- Compression:
- Scoring:
- Expansion: , where = tokens per chunk.
Total cost:
Break-even condition:
When , ReFrag yields massive savings.
PyTorch Prototype
import torch
import torch.nn as nn
class FragmentCompressor(nn.Module):
def __init__(self, d_in=768, d_out=128):
super().__init__()
self.linear = nn.Linear(d_in, d_out)
def forward(self, x):
return self.linear(x)
class ReFragPipeline(nn.Module):
def __init__(self, d_in=768, d_out=128, d_model=256, n_heads=4):
super().__init__()
self.compressor = FragmentCompressor(d_in, d_out)
self.cross_att = nn.MultiheadAttention(d_model, n_heads, batch_first=True)
self.q_proj = nn.Linear(d_in, d_model)
self.k_proj = nn.Linear(d_out, d_model)
self.v_proj = nn.Linear(d_out, d_model)
def forward(self, query, frags, topk=5):
z = self.compressor(frags) # Compress
scores = torch.einsum('bd,bnd->bn', query, z)
topk_idx = torch.topk(scores, k=topk, dim=1).indices
batch_idx = torch.arange(frags.size(0)).unsqueeze(-1).expand_as(topk_idx)
z_sel = z[batch_idx, topk_idx] # Select top-k
Q = self.q_proj(query).unsqueeze(1)
K, V = self.k_proj(z_sel), self.v_proj(z_sel)
out, _ = self.cross_att(Q, K, V) # Cross-attend
return out.squeeze(1)
# toy run
B, N, d_in = 2, 10, 768
frags = torch.randn(B, N, d_in)
query = torch.randn(B, d_in)
model = ReFragPipeline()
final_repr = model(query, frags)
print(final_repr.shape)
Discussion & Open Questions
- Fragment granularity: How to best split documents, sliding windows or semantic boundaries?
- Compression functions: Linear is simple; could autoencoders yield better trade-offs?
- Adaptive budgets: Can expansion depend dynamically on query difficulty?
- Diversity term optimization: Exact determinant is expensive, need efficient surrogates.
Key Takeaway
ReFrag reframes retrieval compression as a fragment-level low-rank approximation with adaptive expansion. By fragmenting, compressing, scoring, and then expanding, it preserves semantic signals at a fraction of the token cost.
In short: it’s not just about making things smaller, it’s about compressing the right fragments.