Prefix Tuning
This is the paper introduced by Xiang Lisa Li & Percy Liang from Stanford University.
Paper Link: Prefix Tuning: Optimizing Continuous Prompts for Generation
Let's break it down.
Points from Abstract:
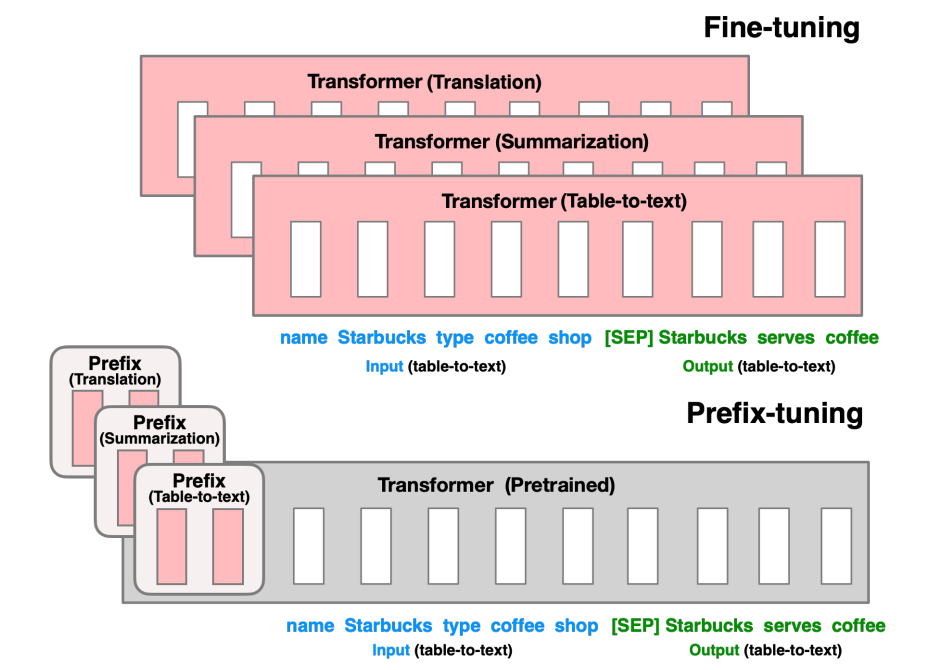
- Fine-tuning is the one and only legitimate way to leverage large pretrained models to perform downstream tasks.
- In this paper, the authors proposed a prefix-tuning, a light-weight alternative to fine-tuning for Natural Language tasks, which keeps language models' parameters frozen, but optimizes a small continuous task-specific vector (called the prefix)
- This allows subsequent tokens to attend to this prefix as if it were virtual tokens.
- By learning only 0.1% of the parameters, the prefix tuning obtains comparable performance in the full data setting, outperforms fine-tuning in low data settings, and extrapolates better to examples with topics unseen during training.
- So, there will be a pretrained model which will be frozen, however, we will use the continuous vectors called prefixes, which are different for each task.
1. What problem are we solving?
You’ve got a big, pretrained language model . You want it to perform a new task (summarize, translate, classify...) without updating all of (which is expensive, slow, and can cause forgetting).
Prefix-Tuning says:
→ Keep frozen.
→ Learn a tiny set of task-specific parameters , called a prefix, that "steer" the model.
Think of the prefix as a tiny “task memory” that the model reads before it reads the actual input.
2. First principles: Conditioning a language model
A decoder-only LM predicts tokens by:
Full fine-tuning: Change
Prefix-Tuning: Keep fixed, and introduce auxiliary variables that modify computation:
We optimize to maximize likelihood on the task; stays frozen.
3. Where does the prefix live? (Inside attention)
Recall a single self-attention head:
Normally, come from the past tokens (causal mask).
Prefix-Tuning augments every layer’s attention with extra key–value pairs that don't correspond to actual tokens.
For layer :
Where:
are learned and task-specific (parameters ).
The queries come from your actual input as usual.
So attention becomes:
Interpretation:
Before looking at the real context, each query attends to learned “memory slots” that encode task instructions or biases.
4. How are prefixes parameterized?
Naively, you could learn directly.
Instead, the paper proposes a reparameterization:
Start from virtual token embeddings:
Pass them through a small 2-layer MLP to generate per-layer key-values:
This keeps parameter count small and stable.
In encoder–decoder models (like T5), you add prefixes to:
- encoder self-attention
- decoder self-attention
- encoder–decoder cross-attention
(with separate 's for each)
5. Training objective (simple)
Freeze . Optimize using maximum likelihood:
Backpropagation flows only into .
→ That’s why Prefix-Tuning is parameter-efficient and fast to adapt.
6. Why does this work? (The math intuition)
Look at the attention logits with concatenated keys:
The first block:
adds learned, content-dependent biases to the attention distribution.
After softmax, the model can shift some probability mass toward prefix slots and mix in their values .
Result: You can shape what each layer “pays attention to,” effectively steering the network’s computation path without editing its weights.
Alternate view: a learned basis
Each layer’s output is an affine combination of values .
By augmenting with learned , you expand the span of representable outputs, like adding a small, learnable basis the model can project onto for this task.
7. How is this different from other PEFT methods?
PEFT: Parameter-Efficient Fine-tuning
Prompt Tuning (soft prompts only at input):
- Adds learnable embeddings only at layer 0 (input).
- Prefix-Tuning adds per-layer key/value pairs, giving deeper control.
- Empirically stronger on generation with fewer params.
Adapters:
- Insert small MLP blocks inside each layer and train them.
- Strong, but requires forward changes and slightly more latency.
LoRA:
Learn low-rank updates to weight matrices: , , ,
Fine-grained and strong on many tasks; touches more places than prefixes.
Tradeoff:
Prefixes = no weight injections, just extra KV, simple to serve and compose.
8. Quick Recap (Mental Model)
- A Transformer layer decides via attention where to look.
- Prefix-Tuning gives it a learned place to look, a tiny, per-layer memory that encodes what this task wants.
- Training only shapes that memory, the big model (parameters ) remains frozen.
9. Pytorch-ish Pseudocode
# given frozen model, learnable PrefixModule
Kp_l, Vp_l = prefix_module() # list over layers, shapes: [L, m, d_k]
for l in layers:
K_star = cat([Kp_l[l], K_l], dim=1)
V_star = cat([Vp_l[l], V_l], dim=1)
out = attn(Q_l, K_star, V_star) # rest unchanged
loss = cross_entropy(outputs, targets) # backprop ONLY into prefix_module
10. Brain-Teaser
If we only added learnable keys , but not values , what behavior would you expect during attention, and why?
Queries ( Q ) can still produce attention logits with those prefix keys: . So, the attention distribution can still shift probability mass toward the prefix slots.
But since the corresponding values are missing (or zero), attending to them doesn’t inject any new information. It's like pointing to an empty memory slot.
That means attention is wasted on meaningless content, and the model can't effectively adapt to the task.
The real issue isn’t "no bias", it’s "no useful content."
Attention requires both:
- Where to look (keys ( K ))
- What to retrieve (values ( V )) Without values, the prefix can't steer computation.
The refinement: keys alone create positions, but without values, those positions hold nothing, so the model can’t change behavior.
A. Normal Attention (No Prefix)
The attention mechanism:
With:
Each row of gives attention logits → softmax → weights to average rows of .
So:
- Keys = where to look
- Values = what to retrieve
B. With Full Prefix
Augment keys and values:
Now attention becomes:
Queries can now spread attention across both:
- : task-specific prefix keys
- : regular keys from input
If attention shifts to , the model retrieves corresponding , which is learnable → task-specific information enters computation.
C. With Only Prefix Keys (No Prefix Values)
We still augment keys:
But now the values are:
So attention becomes:
D. Why This Collapses
The logits term:
So:
- Probability mass can shift toward prefix slots
- But their values are all zero, so:
Net effect:
- Attention on the prefix is wasted
- Model only gets info from regular
- So it can’t adapt to the new task
What happens during training?
The model learns to avoid prefix keys entirely → logits pushed to , prefix gets ignored.
Intuition Check:
Keys without values create empty memory addresses. Attention can point to them, but there's nothing to retrieve.
Soft Prompt Implementation
import torch
import torch.nn as nn
class SoftPrompt(nn.Module):
def __init__(self, prompt_length, embedding_dim):
super(SoftPrompt, self).__init__()
self.prompt_embeddings = nn.Embeddings(
prompt_length, embedding_dim
)
def forward(self, input_ids):
prompt_ids = torch.arange(
self.prompt_embeddings.num_embeddings,
device = input_ids.device
)
prompt_embeddings = self.prompt_embeddings(prompt_ids)
return torch.cat(
(prompt_embeddings, input_ids), dim = 1
)
Prefix Tuning Implementation
import torch
import torch.nn as nn
class PrefixTuning(nn.Module):
def __init__(self, prefix_length, embedding_dim, num_layers):
super(PrefixTuning, self).__init__()
self.prefix_embeddings = nn.Embeddings(
prefix_length * num_layers, embedding_dim
)
self.prefix_length = prefix_length
self.num_layers = num_layers
def forward(self, input_ids):
batch_size = input_ids.size(0)
total_prefix_length = self.prefix_length * self.num_layers