Mixture of Experts (MoE) [Theory and Implementation]
In this, we will learn about the MoEs and Sparse MoEs; both are mostly the same, but different in use cases. This can be used for the last-minute revision for the interviews OR learn with maths intuition...
This is not a new concept made by DeepSeek. The MoE was first coined by Prof. Geoffrey Hinton and later on used by DeepSeek tactically in the FFNs.
Paper Link: DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
My Implementation from scratch: MoE_Implementation
Mixture of Experts Architecture
MoEs in the Large Neural Networks
MoEs in the DeepSeek

MoEs in Switch Transformer
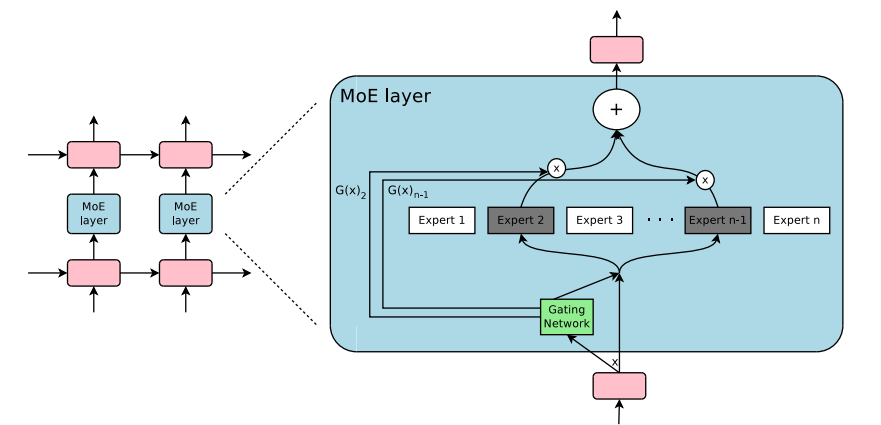
The Mixture of Experts (MoE) is a neural network architecture that uses a set of expert networks to solve tasks, while a gating network determines which experts to use for each input. Instead of using all experts for every input, the MoE model uses a sparse of experts(usually a small number) to make predictions, improving efficiency and scalability.
It is divided into three parts: Expert Networks, Gating Networks, Combination of Outputs
Important Formulas
- Input:
- Expert Network Output:
- Gating Network (score for expert ):
, where is the sigmoid function - Top- Selection (by gate scores):
, where are the top- values - Final MoE Output (Weighted Sum of Top- Experts):
$$ y_{\text{final}} = \sum_{k=1}^{K} g_{i_k}(x) \cdot f_{i_k}(x) $$
1. The Core Intuition of MoE
At the simplest level:
Standard neural nets: every parameter is active for every input.
MoE: only a small subset of parameters (experts) are activated depending on the input.
Think of it as a committee of specialists. A question comes in → the "gating mechanism" picks which specialists should answer → the final output is the weighted combination of their answers.
This gives:
- Scalability → you can have billions of parameters but use only a fraction per input.
- Specialization → different experts handle different parts of the data distribution.
2. Basic Math of MoE
Let’s formalize.
Suppose:
Input token representation:
We have experts, each is a function . For simplicity, think of each expert as an MLP layer.
The MoE layer output is:
Where:
- = the output of the -th expert
- = gating function weight for expert (probability-like, usually from a softmax)
Gating Function:
Here is a learnable matrix.
In sparse MoE (most popular in practice, e.g., Switch Transformer, GLaM):
We don’t use all experts.
Instead, we select the Top-K experts (say, 1 or 2) with highest gate score.
So effectively:
3. Intuition of Mathematics
The gating mechanism is like a router that decides which expert to call.
Training encourages experts to specialize in handling different types of tokens (e.g., numbers vs. code vs. natural language).
By using Top-K, we make the computation cheap: we don’t run all experts, just a few.
Efficiency gain:
Suppose experts, each with 50M parameters → 3.2B parameters total.
If we use Top-2 experts per input, the effective compute per token is ~100M parameters (instead of 3.2B).
So you get the capacity of a giant model with the compute of a smaller one.
4. Architectures of MoE
(A) Shazeer et al. (2017) – Sparsely Gated MoE
- First popularized MoE for language models.
- Each token routed to Top-K experts.
- Introduced load balancing loss to prevent some experts from being overused.
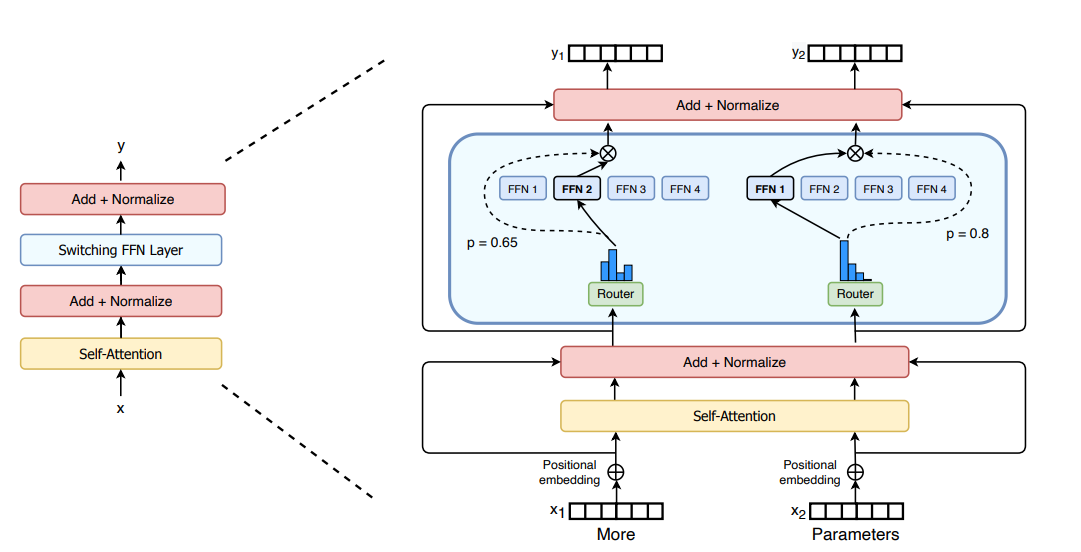
(B) Switch Transformer (Google, 2021)
- Simplification: route each token to only one expert (Top-1).
- This reduces communication overhead and makes scaling easier.
- Huge scaling: trained a 1.6 trillion parameter model with MoE.
Equation:
5. Training Challenges & Solutions
Load Imbalance:
Some experts get all tokens, others are idle.
Solution: Add auxiliary loss to encourage balanced usage.
Example:
Routing Instability:
Gate may change suddenly → unstable learning.
Solution: Use noise, temperature scaling, or smooth routing.
Communication Overhead:
Sending tokens to multiple experts across GPUs is expensive.
Solution: Use all-to-all optimized kernels (e.g., DeepSpeed-MoE).
6. Backpropagation Derivation (Single Token, Single MoE Layer)
Setup & Notation
Input:
Experts: experts, indexed by
Each expert is a 2-layer FFN:
Router logits:
Temperature:
Softmax gate probabilities:
Top-K (hard mask):
Renormalized combine weights:
Layer output:
Loss:
Upstream gradient:
Step 1: Gradients w.r.t. Expert Outputs and Combine Weights
Since :
For (if ):
For (if ):
Step 2: Gradients Inside Each Expert
Let
Then:
Expert contribution to input gradient:
Only experts receive/use these gradients.
Step 3: Gradients w.r.t. Masked Softmax Weights
We treat as a softmax over masked logits:
Softmax Jacobian (restricted to ):
Chain rule to logits:
Then:
And for .
Why Use Instead of Just 1?
Softmax is multi-dimensional, not independent.
Each output depends on all logits, so the derivative is a Jacobian.
If (self-derivative):
If (cross-derivative):
Using gives both in one clean formula:
Step 4: Router Gradients
Given :
Router’s contribution to input gradient:
Step 5: Total Input Gradient
Sum of expert and router contributions:
7. What Interviewers Love to Probe in MoE Architectures
Who gets the gradient?
- Only the selected experts (for that token) receive gradients from the main loss.
- The router gets gradients only through the selected values i.e., for experts in the Top- set.
- Unless you use Top-1 without scaling ("Top-1-no-scale"), the router gradient is sparse.
- Auxiliary losses (like load balancing or entropy loss) are often used to improve the router training signal.
Router–Input Coupling
The input gradient includes a router path:
This means the routing decisions affect not only the expert weights but also the upstream features and gradients i.e., the router is coupled with input representations.
It’s not just about deciding which expert gets used it also shapes the input representation during training.
Top-1 vs Top-K Trade-Off
Top-1 Routing (Switch Transformers):
- Only one expert per token.
- Simpler and faster.
- But: No gradient signal to the router from the main loss unless:
- You scale the expert output by the probability .
- Or add a strong auxiliary loss to guide the router.
Top-K Routing:
- Allows richer combinations and more robust gradients.
- Slightly more computationally expensive than Top-1.