KV Caching
A small note on the KV Caching. In short, it is the most powerful trick that makes LLM faster during inference.
Let's deep dive into this...
1. Where the problem comes from
At inference (say, autoregressive generation), you generate tokens one at a time:
Step 1: Input prompt → predict next token.
Step 2: Append predicted token → feed full sequence again → predict next.
Step 3: Repeat…
Naïvely, at each step you’d recompute attention across the entire prefix plus all past tokens. That’s a computational cost of as the sequence grows, way too slow.
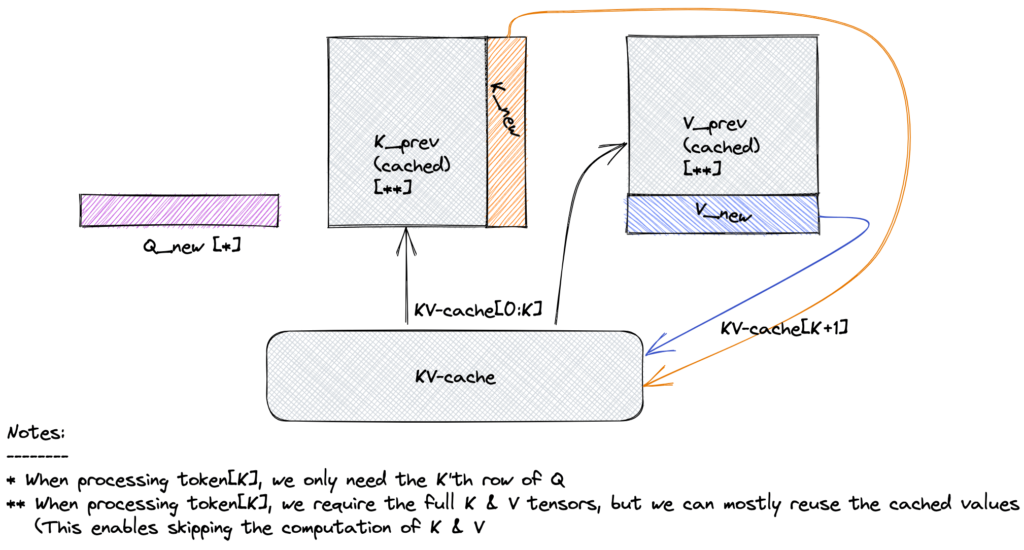
2. The Trick: Cache , Once
Attention formula:
Notice:
Keys and values come from all previous tokens (including the prefix).
At time , you don’t need to recompute . You already had them at step .
You only need to compute for the new token, then append them.
So each step just does:
Instead of reprocessing the whole history.
3. What’s Actually Cached?
For every layer :
Store the matrices and for all tokens generated so far.
In practice, they’re stored in shape:
-
- batch_size: number of sequences processed in parallel
- num_heads: number of attention heads
- seq_len: number of tokens seen so far
- : dimensionality of each key vector per head
During generation:
- Forward pass for the new token computes only its , , .
- Append new , to cache, use cached , for attention.
4. Why This Helps
- Without caching: recompute for all tokens at each step → .
- With caching: compute only once per token, then reuse → .
This is why large LMs (like GPT) can generate long sequences in real time.
5. Prefix-Tuning Twist
In Prefix-Tuning, the prefix KV pairs (, ) are constant across steps (they don’t change with new tokens).
You can pre-compute them once per task and store them in the cache at the start.
At inference, they’re concatenated with the cached KV from real tokens:
That means every query token can always attend to both prefix memory and past tokens without recomputing either.
So, KV caching + prefix tuning = super efficient adaptation:
- Prefix KV computed once
- Token KV computed incrementally
6. KV Caching in a Nutshell
That’s KV caching in detail:
- It stores past keys and values per layer
- Reuses them across decoding steps
- Makes autoregressive inference cost instead of
- And in Prefix-Tuning, it makes prefixes basically “free” after the first compute